

Incident management shouldn’t feel like herding cats during a thunderstorm. Yet here we are, watching teams juggle seventeen different tools while their production systems burn down around them. However, Rootly AI brings sanity to this madness through intelligent automation that actually works.
Look, I’ll be honest—if a tool like this had existed just five years ago, it would’ve saved me countless headaches working with startups. We had so many war rooms spinning up in Slack during outages that tracking everything became impossible. One incident would spawn three different channels, each with partial context and confused stakeholders jumping between conversations. Additionally, critical updates got buried in message threads while engineers scrambled to coordinate fixes.
This isn’t another “revolutionary” platform that promises everything and delivers nothing. Furthermore, it transforms chaos into coordinated responses through AI that enhances rather than replaces human decision-making.
Your Current Incident Response Is Probably Broken
Most incident management systems were designed by people who never spent 3 AM debugging a database crash. Teams waste critical minutes switching between monitoring dashboards, Slack channels, and ticket systems. Additionally, everyone’s working from different information, creating confusion when precision matters most.
These broken patterns keep repeating:
- Critical alerts getting lost in noisy Slack channels
- Senior engineers becoming single points of failure
- Post-incident reviews that collect dust in Confluence
- Escalation policies that nobody remembers during emergencies
- Customers finding out about outages through Twitter
Consequently, your best people start avoiding on-call duties, and customer trust erodes with every botched response. According to Atlassian’s incident management research, organizations without structured incident processes face significantly longer recovery times.
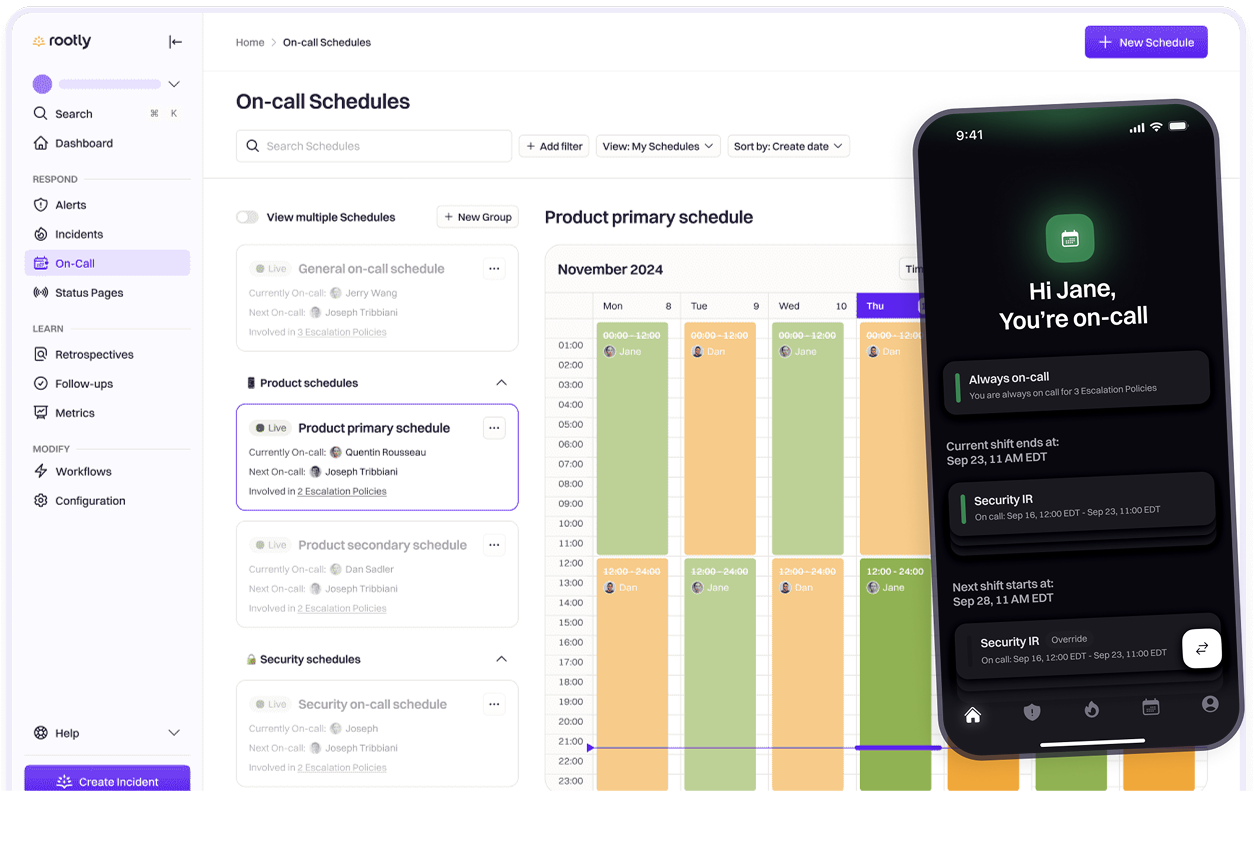
How Rootly Brings Intelligence to Crisis Management
Rootly operates where your team already lives: inside Slack. The platform transforms scattered conversations into structured incident response through customizable workflows. Moreover, AI capabilities handle documentation and communication automatically, freeing teams to focus on solutions.
Slack-Native Orchestration That Makes Sense
Simple slash commands instantly create dedicated incident channels with proper context and stakeholder access. Rootly automatically configures integrations with Zoom for emergency bridges and Jira for task tracking. Therefore, coordinated responses happen naturally without tool switching.
The system understands team structures, expertise areas, and availability patterns. Additionally, it routes incidents intelligently based on real-time data rather than static assignment rules.
AI-Powered Documentation That Actually Helps
Rootly’s AI watches incident conversations and generates comprehensive summaries automatically. No more assigning someone to take notes while everyone else troubleshoots. Furthermore, the system drafts customer communications and internal status updates in your organization’s voice.
Machine learning adapts to your team’s communication patterns and suggests relevant runbooks or documentation. Meanwhile, engineers stay focused on problem-solving rather than administrative overhead.
Follow-Up That Actually Follows Through
Post-incident action items usually disappear into the productivity tool graveyard. Rootly uses emoji-based task assignment that feels natural within Slack workflows. Team members can create, assign, and track follow-up work without leaving the conversation context.
Automated reminders and progress tracking ensure critical improvements actually happen. Consequently, those security patches and infrastructure upgrades don’t get forgotten during the next sprint planning.
On-Call Management That Preserves Sanity
The web platform aggregates all incident data into actionable insights rather than vanity metrics. Teams access detailed retrospectives, performance analytics, and trend identification from a unified interface. Additionally, sophisticated scheduling manages complex rotations across time zones and individual preferences.
Dynamic Escalation That Learns
Rootly’s escalation policies evolve based on historical incident resolution patterns. The system considers current workload, subject matter expertise, and response availability before routing alerts. Therefore, load balancing happens automatically while maintaining rapid response capabilities.
Smart routing prevents senior engineer burnout by distributing incidents based on complexity and expertise requirements. Furthermore, junior team members gain exposure to appropriate incidents for skill development.
Analytics That Drive Meaningful Change
Most incident metrics are theater designed to impress executives rather than improve operations. Rootly surfaces patterns that enable proactive improvements: recurring failure modes, team performance variations, and system reliability trends. Additionally, customizable dashboards provide relevant insights for different stakeholder groups.
For comprehensive strategies on operational excellence and team resilience, explore our extensive resource collection covering modern engineering practices.
Integration Ecosystem That Enhances Rather Than Replaces
Modern incident management requires seamless connectivity with monitoring platforms like Datadog, alerting systems like PagerDuty, and observability tools like New Relic. Rootly connects existing toolchains rather than forcing wholesale replacements. Therefore, teams enhance current workflows while maintaining institutional knowledge.
Flexible APIs enable custom integrations for specialized internal systems. Additionally, webhook support provides real-time data synchronization across platforms your organization already trusts.
The Honest Assessment: What Results Actually Look Like
Organizations implementing Rootly typically reduce mean time to resolution by 40-60% within the first quarter. Engineer satisfaction improves because on-call becomes predictable rather than chaotic. Furthermore, customer communication becomes proactive instead of reactive damage control.
Now, some skeptics might argue that adding another platform increases complexity rather than reducing it. Every tool promises to be “the last one you’ll need.” However, Rootly’s Slack-native approach actually consolidates workflows rather than fragmenting them further.
Measurable improvements include:
- Faster incident detection through intelligent alert routing
- Reduced communication overhead during crisis situations
- Improved post-incident learning through automated documentation
- Better work-life balance for on-call engineers
- Enhanced customer trust through transparent communication
Implementation Strategy That Actually Works
Successful Rootly deployment starts with mapping current incident workflows and identifying automation opportunities. Begin with pilot implementation for a single service or team to refine configurations. Additionally, gradual rollout allows iterative improvement based on real-world usage patterns.
Essential implementation considerations include:
- Defining clear incident severity classifications and response procedures
- Configuring integrations with existing monitoring and alerting infrastructure
- Establishing escalation policies that account for global team distribution
- Training stakeholders on AI-assisted workflows and automation capabilities
- Setting baseline metrics to measure improvement over time
Change management becomes critical for adoption success. Therefore, involve key engineers in configuration decisions and gather feedback throughout the rollout process. Google’s SRE practices emphasize the importance of structured incident management processes for successful implementation.
The Future of Intelligent Incident Response
Rootly represents evolution toward self-improving incident management that adapts continuously. Machine learning capabilities will expand into predictive failure analysis and automated remediation suggestions. Furthermore, AI will optimize resource allocation and response strategies based on historical patterns.
Organizations investing in intelligent incident management gain competitive advantages through improved system reliability and faster recovery capabilities. Additionally, they build more resilient engineering cultures that attract top talent.
The companies that thrive in the next decade will be those that embrace intelligent automation while preserving human creativity and judgment. Modern incident management tools provide the foundation for building that operational excellence today.
Embracing the AI Revolution in Operations
Tools like Rootly represent just the beginning of what’s possible when we utilize artificial intelligence thoughtfully. Remember, this technology exists to make teams more efficient, not to replace them entirely. Think about the design world—when Figma emerged, everyone panicked about learning yet another tool after mastering Sketch.
Initially, designers resisted the change. “Why should we abandon our workflows?” they asked. However, those who embraced Figma early gained collaborative superpowers that set them apart from competitors still stuck in outdated processes. Similarly, engineering teams that adopt AI-powered incident management today will develop operational advantages that compound over time.
The pattern repeats throughout technology history. Teams that resist useful innovations eventually find themselves at a disadvantage, while early adopters gain competitive edges through improved efficiency and capabilities. Therefore, the question isn’t whether AI will transform incident management—it’s whether your team will lead or follow this transformation.


